

<요약>
- 인터넷Internet은 웹의 핵심적인 기술이다.
- 인터넷은 컴퓨터를 서로 연결하여 TCP/IP라는 통신 프로토콜을 이용해 정보를 주고받는 컴퓨터 네트워크이다.
- 인터넷 변화 양상① 컴퓨터 ↔ 컴퓨터② 컴퓨터 ↔ 라우터 ↔ 컴퓨터③ 컴퓨터 ↔ 라우터 ↔ 라우터 ↔ 컴퓨터④ 컴퓨터 ↔ 라우터 ↔ 모뎀 ↔ 전화 시설 ~⑤ 컴퓨터 ↔ 라우터 ↔ 모뎀 ↔ 전화 시설 ↔ ISP (↔ ISP) ↔ 전화 시설 ↔ 모뎀 ↔ 라우터 ↔ 컴퓨터
<인터넷의 시작>
인터넷은 1960년대 미국 국방성에서 기금한 연구 프로젝트에서 시작되었다. 소련에서 처음으로 인공위성을 발사하는 데 성공하자 이에 위협을 느낀 미국은 새로운 기술을 연구하는 ARPAAdvanced Research Projects Agency, 고등 연구 계획국 부서를 창설하였고, ARPA는 1969년 현재 웹의 모태가 되는 ARPANET을 개발하였다. ARPANET은 핵과 같은 공격에 대비하여 전체 통신 시스템에서 데이터를 안전하게 보관 및 전송할 수 있는 시스템이다.
핵과 같이 광범위한 지역을 타격할 수 있는 무기가 탄생하면서, 한 곳이 타격되면 모든 데이터가 소실될 수 있는 기존 중앙 집중화된 데이터를 물리적으로 분산 저장(like 백업)하여 데이터를 보관하려는 요구가 있었을 것이다. 또한 분산 저장 시 데이터 전송, 동기화 등의 문제를 해결할 수 있는 방법을 모색했을 것이다. 따라서 각 데이터 센터를 연결하는 통신 시스템을 만들 필요가 있었고, 그렇게 만들어진 것이 ARPANET으로 보인다.
초기에 ARPANET은 미국 국방성과 대학교를 연결하였다. 1983년 ARPANET은 민간 연구용의 작은 네트워크과 군사용 MILNETMilitary Network으로 나누어졌고, 여기서 민간 연구용의 ARPANET이 현재 전 세계의 모든 컴퓨터를 연결하고 있는 인터넷으로 발전하였다.
인터넷을 지원하는 다양한 기술을 시간이 지남에 따라 진화해왔지만 작동 방식은 그다지 변하지 않았다.
<'인터넷'의 어원>
인터넷이란 이름은 1973년 TCP/IP를 정립한 빈튼 서프Vinton Gray Cerf와 로버트 칸Robert E. Kahn이 '네트워크의 네트워크'를 구현하여 모든 컴퓨터를 하나의 통신망 안에 연결(International Network)하고자 하는 의도에서 이를 줄여 인터넷(Internet)이라고 처음 명명하였던 것에 어원을 두고 있다.
<인터넷의 변화>
1) 단순한 네트워크
① 1:1 연결
두 대의 컴퓨터가 통신이 필요할 때, 우리는 다른 컴퓨터와 물리적으로 (보통 이더넷 케이블, 일반적으로 우리가 말하는 '랜선') 또는 무선으로 (WiFi 나 Bluetooth) 연결되어야 한다. 모든 현대 컴퓨터들은 이러한 연결 중 하나를 이용하여 연결을 지속할 수 있다.
앞으로 나올 예시에서의 '연결'은 유선 네트워크와 관련해서만 이야기하지만, 유선 네트워크와 무선 네트워크는 동일한 방식이다.
두 대의 컴퓨터를 연결한다고 가정했을 때, 아래와 같은 모양일 것이다.
② 多:多 연결
우리는 1:1로 연결하는 방식과 같은 방식으로 원하는만큼 컴퓨터를 연결할 수 있다. 하지만 이렇게 연결할 경우 컴퓨터의 수가 늘어날수록 매우 복잡해진다. 1:1로 연결하는 방식으로 10대의 컴퓨터를 연결한다고 생각해보자.
이 경우 컴퓨터마다 9개의 플러그가 필요하고, 45개의 케이블이 필요하다.
③ 라우터 연결
위 문제를 해결하기 위해 네트워크의 각 컴퓨터는 라우터(Router)라고하는 특수한 소형 컴퓨터에 연결된다. 이 라우터는 단 하나의 작업만 있다. 철도역의 신호원처럼 주어진 컴퓨터에서 보낸 메시지가 올바른 대상 컴퓨터에 도착하는지 확인하는 것이다. 컴퓨터 B에게 메시지를 보내려면 컴퓨터 A가 메시지를 라우터로 보내야하며, 라우터는 메시지를 컴퓨터 B로 전달하고 메시지가 컴퓨터 C로 전달되지 않도록 해야 한다.
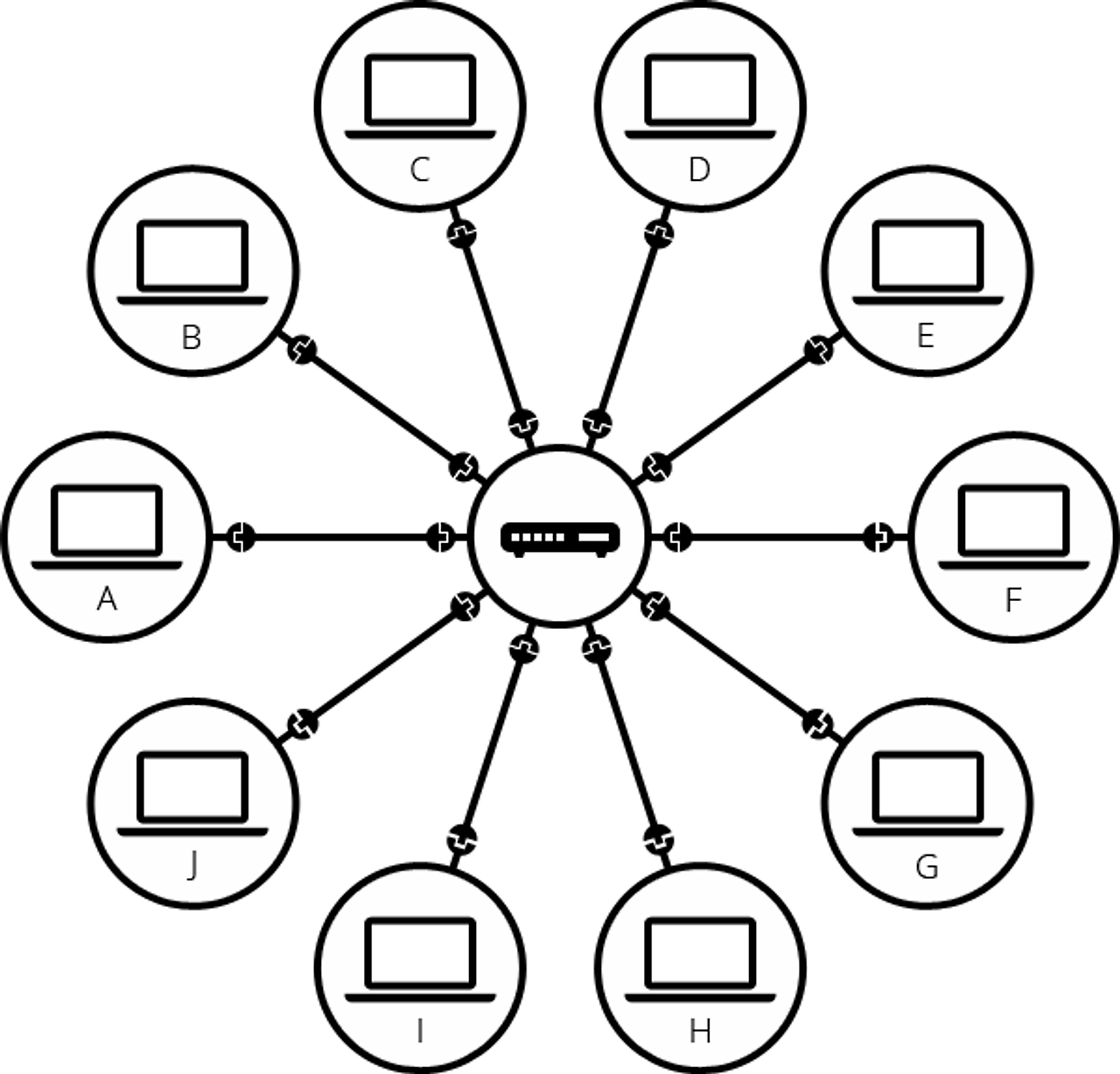
위 그림과 같이 이 라우터를 시스템에 추가하면 10대의 컴퓨터 네트워크에는 10개의 케이블만 필요하다. 각 컴퓨터마다 단일 플러그와 10개의 플러그가 있는 하나의 라우터만이 필요하게 된다.
2) 네트워크 속의 네트워크
그렇다면 수 백, 수 천, 수 십억 대의 컴퓨터를 연결하려면 라우터에 그만큼의 플러그가 필요하고 모든 컴퓨터가 연결되어야 할까? 일단, 라우터 자체로도 그 정도까지 확장할 수 없다. 그렇다면 어떻게 해야할까?
앞서 라우터 또한 '컴퓨터'라고 했었다. 따라서 두 대 이상의 라우터도 연결할 수 있다! 아래 그림은 각각의 라우터로 연결된 두 개의 네트워크를 연결한 모습이다.
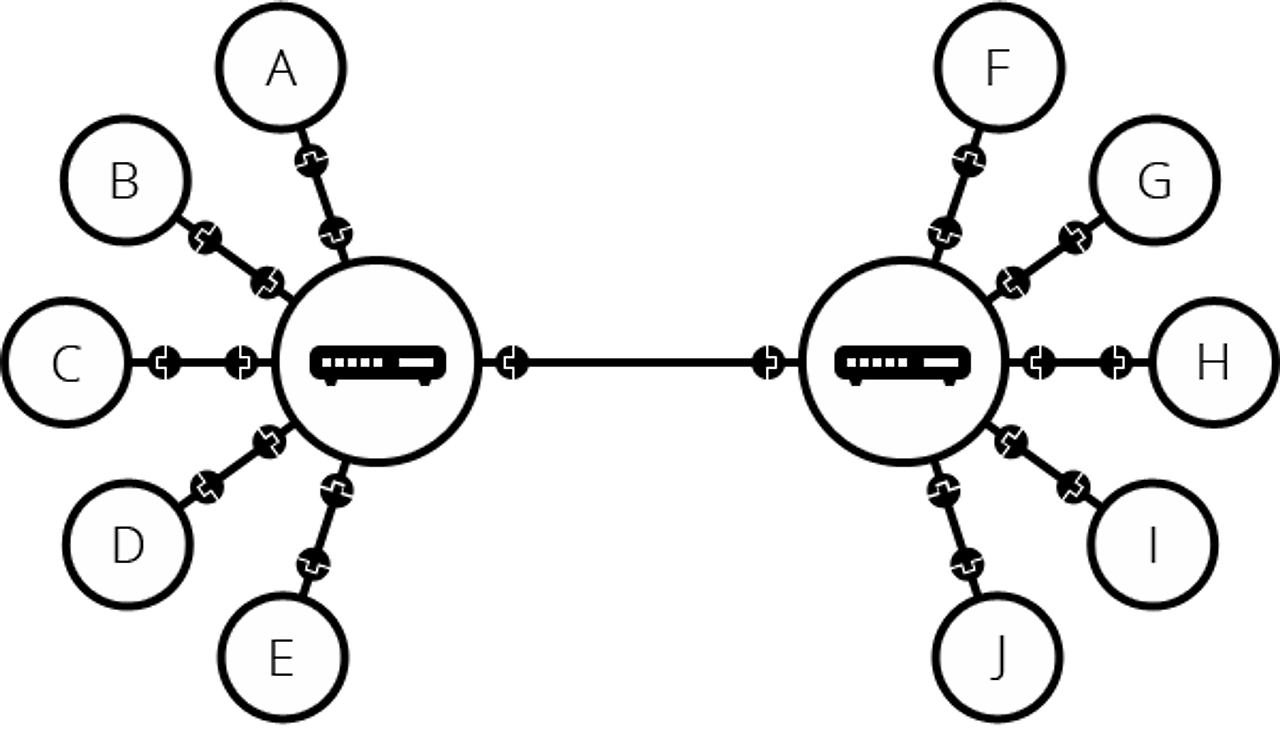
즉, 컴퓨터를 라우터에 연결하고, 라우터에서 라우터로 연결함으로써 연결을 무한히 확장할 수 있다.
이러한 네트워크는 우리가 인터넷이라고 부르는 것에 매우 가까워졌다. 상대적으로 많은 컴퓨터를 적은 케이블로 연결할 수 있어졌다. 하지만 아직까지 우리에게는 물리적 한계가 존재한다. 예를 들어 아주 먼 곳까지, 수 십개의 라우터를 유선 케이블로 연결할 수는 없을 것이다. (사실 연결할 수는 있겠지만, 만약 서울에 거주 중인 누군가가, 부산 본가까지 네트워크 연결을 위해 랜선을 연결하듯이 400km의 유선 케이블을 설치해야 한다고 생각해보자..lol) 그렇다면 이 문제를 어떻게 해결할 수 있을까?
우리는 이미 모든 집집마다 연결된 케이블이 있다. 바로 '전화선'이다. 우리의 선배님?들은 이 전화선을 통해 장거리 네트워크에 연결하기로 했다. 우리의 네트워크와 전화 시설을 연결하기 위해선, 모뎀(MODEM, MOdulator and DEModulator)이라는 특수 장비가 필요하다.
모뎀은 우리 네트워크의 정보를 전화 시설에서 처리할 수 있는 정보로 바꾸며, 그 반대의 경우도 마찬가지이다.
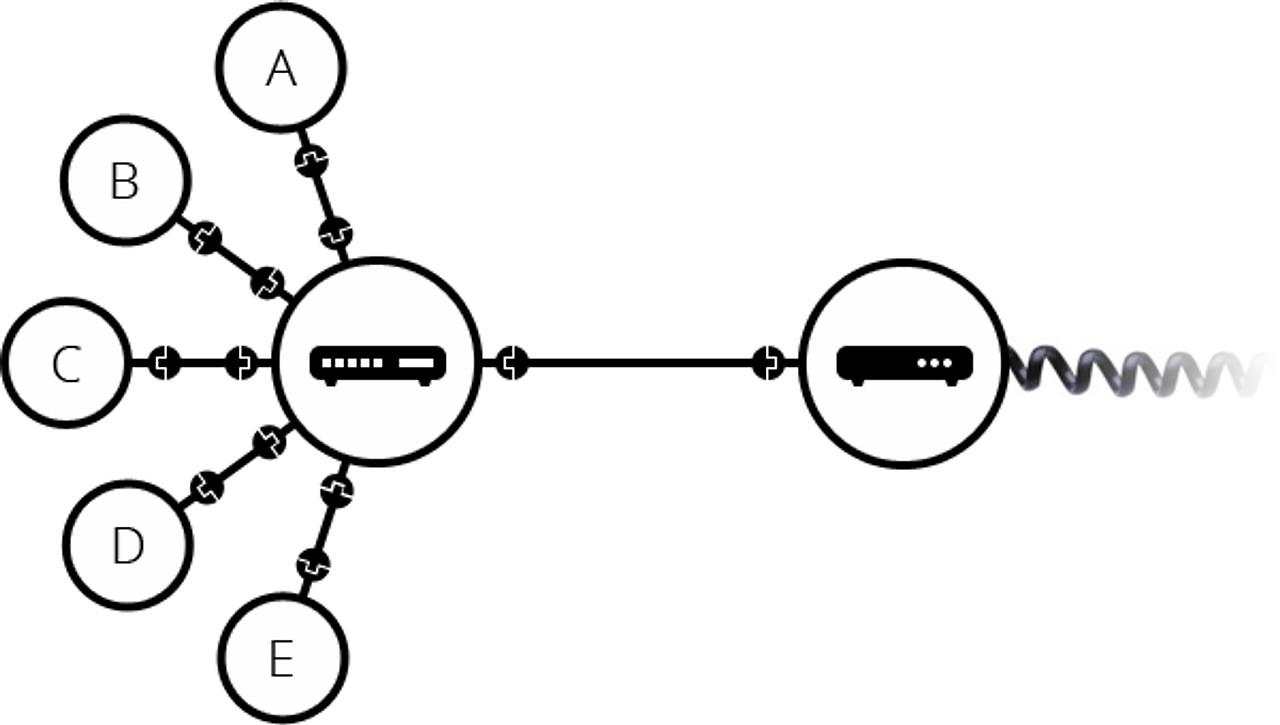
모뎀을 통해 우리의 네트워크는 전화 시설에 연결된다. 하지만, 아직까지 우리의 컴퓨터가 보낸 메시지가 도달해야 할 컴퓨터(혹은 네트워크)까지 도달하지 않은 상태다. 이 메시지가 전달되려면 인터넷 서비스 제공 업체(ISP, Internet Service Provider)에 연결되어야 한다.
ISP는 모두 함께 연결되는 몇몇 특수한 라우터를 관리하고 다른 ISP의 라우터에도 액세스할 수 있는 회사이다. 우리나라에는 SK텔레콤, KT, LG유플러스 등이 있다.
따라서 우리 네트워크의 메시지는 ISP 네트워크의 네트워크를 통해 대상 네트워크로 전달된다. 인터넷은 아래 그림과 같이 이러한 전체 네트워크 인프라로 구성된다.
<HTTP (Hyper Text Transfer Protocol), 하이퍼텍스트 전송 프로토콜>
💡 HTTP- HTTP는 서버와 클라이언트가 서로 데이터를 주고받기 위해 사용되는 통신 규약을 말한다.
- 1989년 Tim Berners Lee 팀 버너스리가 처음 설계했으며, 초기 단계에서 발전을 거듭해 현재는 HTML 문서와 같은 정보들을 가져오는데 사용된다.
- TCP/IP(Transmission Control Protocol / Internet Protocol)을 이용하며, 사용 포트 번호는 기본적으로 80이다.
- 인터넷 기반 서비스에는 HTTP 외에도 Email, FTP, DNS, NEWS 등이 있다.
인터넷 주소를 지정할때 http://www.~~~ 와 같이 시작하는 것은 www.~~이라는 인터넷 주소가 가진 데이터 정보 등의 교환을 http의 통신 규약대로 처리하라는 것을 의미한다. 또 HTTP는 애플리케이션 계층의 최상위에 있기 때문에, 기본 레이어들은 HTTP의 명세와는 관련이 없다.
클라이언트 -----메시지-----> 서버를 **요청 (request)**이라고 하며,
서버 -----메시지-----> 클라이언트를 **응답(responses)**라고 부른다.
클라이언트(사용자 에이전트) : 사용자를 대신하여 동작하는 모든 도구를 말한다. 브라우저는 (항상) 클라이언트의 역할을 한다. 브라우저는 절대로 서버가 될 수 없다. 웹페이지를 예로 들면, 브라우저는 페이지에 나타날 HTML 문서를 요청한다 >> 스크립트/이미지/비디오/CSS 등등을 가져온다 >> 이 리소스들을 혼합해 웹페이지에 표시한다.
서버(웹서버) : 통신 채널 반대편에는 클라이언트의 요청을 받아 이 요청에 대한 정보를 제공하는 서버가 존재한다. 요청에 대한 답을 HTTP 메시지(HTTP message)라고 한다.
HTTP는 클라이언트-서버가 메시지를 주고받으면 연결을 끊어버린다. 이 특징을 보완하기 위해 Cookie와 같은 기술이 등장했다. (무상태, Stateless라고 부름)
또 이 요청과 응답 사이에는 여러 개체들이 있는데, 그 중 프록시는 게이트웨이 또는 캐시 역할을 한다.
<프록시>
프록시: 웹브라우저와 서버 사이에 수많은 HTTP 메시지들이 왔다갔다 하는데, 이들이 어떻게 동작하는지 눈에 보이지 않는다. 애플리케이션 계층에서 동작하는 것들을 일반적으로 프록시라고 말한다. 프록시는 눈에 보이거나 그렇지 않을 수도 있으며 다양한 기능들을 수행한다.
- 캐싱 (HTTP로 문서 캐시되는 방식 제어 가능.)
- 필터링 (바이러스 백신 스캔, 유해 컨텐츠 차단 기능)
- 로드 밸런싱 (여러 서버들이 서로 다른 요청을 처리하도록 허용)
- 인증 (다양한 리소스에 대한 접근 제어. HTTP-WWW-Authenticate 또는 HTTP 쿠키를 사용해 설정 가능)
- 로깅 (이력 정보를 저장)
HTTP 메시지는 요청 메시지(Request message)와 응답 메시지(Response message)로 분류된다. (클라이언트에서 온 메시지/서버에서 온 메시지의 차이)
General은 메시지에 대한 일반적인 정보를 제공한다. (요청/응답 전체에 적용)
- Request Method : 클라이언트가 수행하고자 하는 동작 정의 (GET, POST, PUT, DELETE, OPTIONS, HEAD). 일반적으로 GET(클라이언트가 리소스를 가져옴)이나 POST(HTML 폼의 데이터를 전송)를 사용함.
- Statue Code : 200 정상
Response Headers는 response message만 취급.
- date : 메시지 작성 일자
- cache-control : 캐시 사용 제어. (no-cache:캐시 쌓지 않는다 / max-age=seconds:seconds값보다 오래된 응답은 보내지 않는다 / public : 어떤 캐시든 쌓는다 등등)
- content-type : 응답되는 컨텐츠의 유형
- content-length : 응답되는 컨텐츠의 길이
- last-modified : 응답되는 컨텐츠가 마지막으로 수정된 일시
- server : HTTP server의 정보
Request Headers는 request message만 취급.
- authority : 도메인 이름 및 옵션 포트로 이뤄진 URL. (옵션 포트 앞에는 ':'가 붙는다)
- accept-language : 클라이언트가 요청하는 언어
- user-agent : 클라이언트 프로그램 (웹 브라우저)을 표시함.
'네트워크 > 네트워크 관련지식' 카테고리의 다른 글
| 인터넷 속도가 원래 속도로 안 나올때(ex. 1기가로 안나옴) (0) | 2024.09.24 |
|---|---|
| C타입 광신도의 USB 버전별 특징 정리 (0) | 2024.09.21 |
| 비싼 요금제 써도 똑같은 속도일 수 있는 이유 (0) | 2024.09.15 |
| 네트워크에 대한 전반적인 기초 지식 정리 (0) | 2024.08.14 |
| DNS(Domain Name System) (0) | 2024.08.13 |